The Rise of On-site Content Farms


TL;DR: I stumbled upon a practice that I call “on-site content farming”, where otherwise non-spammy companies are creating spammy “howto” articles on their actual website. Content farming is not new, but the fact that it’s being done on the domain of a company whose primary business is not spam is new, at least to me.
I won’t bore you with my life story, but since this article is written from my personal perspective, let’s start with a quick intro. I’m Klaas, the solo everything at Bugsink, a company making error tracking software. I’m a software engineer who thinks he can also run a business.
After building something that I hope is useful to people, I’m now entering the world of internet marketing. Because “useful” is not enough if nobody actually uses it.
Up till now traffic to my site from places like Hacker News, Reddit and GitHub is quite good. Traffic from Google is basically a rounding error, however (and the traffic that I do get is mostly people searching for Bugsink by name).
Time to read up on the state of the art of SEO. I had a vague idea of what it might be about: first, some technical quick wins such as making sure your site is accessible, fast, and easy to crawl. Second, provide “content” of actual value. Finally, I imagined that there would be at least some level of gaming the system, and that I’d face some moral dilemma at some point in the future. After all, there is an entire industry built around SEO.
That industry comes with tools like semrush. So I signed up for a free trial, and clicked on their tool called the “keyword gap” on its “competitive analysis” section.
Stumbling upon the content farm(s)
So here’s (approximately) what I saw (the actual image was taken a few days later):
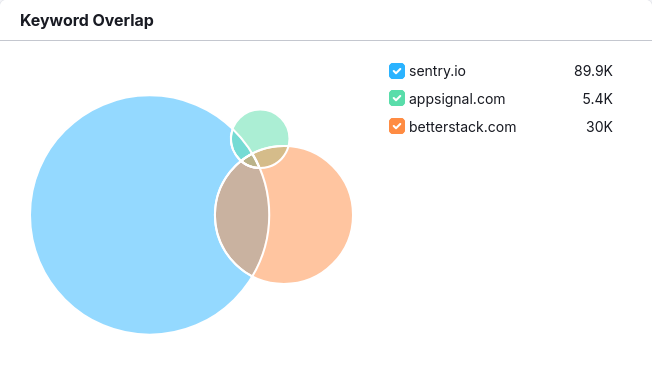
For the uninitiated: the circles represent the keywords that some of my competitors are ranking for. The size of the circle represents the number of keywords that they’re ranking for. The overlap between two circles represents the number of keywords that they’re both ranking for.
Looking at this image, two things immediately popped out at me:
-
The circles are huge, i.e. these competitors are ranking for a lot of keywords.
-
The circles are almost entirely disjoint, i.e. they’re ranking for different keywords. Given that we’re all in the same business, one would expect that we’d be competing for the same keywords. This suggest that the websites are not actually about the company’s products, but about something else.
Clicking on any of the circles, and then on the “unique” tab, showed me the keywords that are unique to that competitor. This indeed confirmed my suspicion. Here are some examples of the pages driving those keywords:
- Converting an integer to a string in PHP
- jQuery is not defined: Common causes and a simple solution
- Generate random integers between X and Y in Python?
- What is the meaning of single and double underscore…
- How to dynamically assign properties to an object in TypeScript
- Documenting your Express API with Swagger
Notice how spammy such a list looks? That’s because it is. In fact, this list looks so spammy that I was afraid to include it here for fear of being associated with it.
So what should we call this? These are simple “howto” articles, explaining some basic concept in a programming language. This is the type of garbage “content” that I’d expect to see on content farms like w3schools, GeeksforGeeks or dev.to.
But here it is right on the website of a supposedly reputable company. That’s why I call it “on-site content farming”.
Content farming
So what’s the problem here? If you have to ask, you’re probably part of the problem, but let me try to explain it anyway.
The first problem is the general problem with content farms: they’re basically spam. This is evidenced by people’s actions when they’re offered the opportunity to block them:
- geekforgeeks and w3schools are in the top blocked domains on kagi.com
- dev.to is shadowbanned on HN
The problem with content farms is that they’re not about providing answers and explanations to help developers understand concepts and avoid future problems. They’re about leading people to the site, where they can be shown ads or sold a product. And that people don’t like that is evindent from their actions when given a choice.
On-site content-farming: worse
The second problem is specific to the on-site case. The content is not only spam, it’s also spam that’s being served on the domain of a company whose primary business is not spam.
When I see dev.to in the URL, I know what I’m getting into. But when I see sentry.io, I expect to see content that’s sentry-related.
It’s like the difference between seeing shady stuff going on in the bad parts of town, or in the most expensive part of town. The former says something about the people in the bad parts: the latter says something about the town itself.
In this case, the prevalence of on-site content farming says something about the state of the internet.
“I’m so happy [random dev tool] wrote about [unrelated dev problem]”
– no one ever
The lameness of it all
There seems to be some (though not much) shame associated with this practice. i.e. the companies seem to at least try to spin this as an actual meaningful portion of their website. For example, the “answers” section of sentry.io has the following description:
Answers and explanations to help developers understand concepts and avoid future problems. Learn why problems happen, not just how to resolve one instance of them.
I don’t think anyone (or at least: any human) is fooled by this.
Also, they put a at least some effort into making it appear (visually) like a real blog. For example, they put the name of the author at the top of the article, and they have a little avatar next to it. But they don’t try very hard: the “authors” at sentry.io have a single character last name (“Naveera A.”), and they have an auto-generated avatar whose filename is literally “ghost-a2df....png“

Again: no humans were fooled.
By the way, if you’re interested in becoming one of these “authors”, the application process is actually quite transparent.
Reputational risk?
What’s the deal with this? Why are these companies doing this? Aren’t they afraid of Google’s wrath? Aren’t they afraid that visitors to the site see this and think “this is evidently a spam company”?
The answers follow from the observed behavior: they’re evidently doing this because it works. And they’re not afraid of the risks (Google’s wrath, reputational risk).
It’s the last one that comes as the biggest surprise to me. I certainly know I wouldn’t want to be caught doing this. That might because in my case, the company is me, and I have a reputation to uphold. But even faceless corporations are sometimes afraid of reputational risk, so I’m not totally sure what makes this different.
Pots and kettles
So what’s the difference between this and what I’m doing myself? Didn’t this article start off with me being open about the start of my SEO journey? Am I not being a hypocrite?
I’d like to think that there’s a difference. On the one hand, there’s me, a real human that’s actually working on things that I care about, and then blogging about them in a way that I hope is interesting to people that might also care about Bugsink. Examples: local variables, simplifying installation.
And yes, I hope that doing this will lead to more customers for Bugsink. But I try to make sure that I’m adding something of value to the day of my readers too. And I’d like to think that because I write about things that I care about, and things that I’m actually working on, that the articles are more relevant to a potential customer than something as random as “how to pick a random number in Python”.
Contrast this with some lowly paid intern from half across the world who, with the help of some AI, is trying to generate as much unrelated “content” as possible in a thinly veiled attempt to lead people to the site. What value is being added in that case? What’s the link with the actual product?
Some counterarguments
Isn’t this the same thing as the article about Forbes that was published a while ago? Not quite: in that case, the model is “use Forbes’ reputation to drive traffic to ads”. Here the model is “use keywords to drive traffic, and then sell your product without ads (cutting out Google). The reputation is still at stake though.
Isn’t this a well known practice? Well, it wasn’t well known to me. I’d love to hear if it’s a prevelant practice in other markets too.
And although it seems to be a well-spread practice in my particular part of the market for developer-tools (Error Tracking), it’s not something that’s being done across the board.
When looking at a very similar market (IDEs), I couldn’t find any examples of this behavior. (I didn’t look very hard, but I didn’t have to look very hard to find examples in the error tracking market, so assumed: “if they’re doing it, I’ll find it quickly”).
Conclusion
So, what’s the conclusion? For me personally, this is an easy one: sure, I imagined the “art of SEO” would involve some moral dilemmas where “writing interesting content” and “writing content that ranks” would be at odds. But this is not such a “close call” for me: this this is not the contribution I want to make to the world. This is not why I started Bugsink.
And for the world at large? I don’t know. I’m not sure what the solution is. I’m not sure if there is a solution short of Google actually caring about this kind of stuff, or greater powers stepping in and making Google care. But I do hope that a little bit of naming and shaming will help to make the internet a better place. Because what else will?